Games matter for humans. Games simulate reality, which is unaccessible for us by some reason. Boys (grown-up and not quite) usually play with gadgets. Girls of any age like behavioral games. Touch interface combines features of both. That's why boys and girls are still playing with it. Paradox is touch interface still does not influence PC world.
Why? The first cause: expensive big touch screens. But it is resolvable by mass production. Another cause is deeper. Can they replace mouse (even not counting that some models have problem with mistake touches)? Mouse accuracy is 1 pixel (which sometimes is enough to call another function). Touch screen accuracy (for finger) is 20-40 pixels (which is enough for an one-word button or 2-3 icons at not mobile screen). To replace mouse, touch screen should be 10-20 times bigger than they are now. But to use them we have to be further away from them, which makes usage of fingers impossible.
However, maybe touch screen devices may just outnumber and replace PCs?
1. The first problem: size mobility. In the essence, a tablet is a notebook or even a netbook without keyboard. One of straightforward reason of tablet popularity is they can be used everywhere, even where usage of notebooks is not comfortable. One minus: typing is awkward and screen is too small (but if we increase size, then we get notebook again).
2. The second problem: energy mobility. Tablet performance is only slightly over notebook one, smartphone performance is much better but its screen size is even smaller.
3. The third problem: text input. Comparing with PCs, typing is slow, error-prone, and is not quite comfortable. In fact, any text media (email or social network messages) in a mobile device finally converts into SMS.
4. The fourth problem: interface. Touch screen has not added value for conventional graphical interface. Except of different way of positioning. This problem described above. Voice control? It is not perfect now, and sometimes it is not acceptable if noise level is quite high or you are in no sound environment. But the bigger problem is modern interface does not suit voice control. Calling menus and submenus with voice control is the anachronism, if you realize that you can call any function without using nested paths to graphical controls (like "File - Open").
5. The fifth problem: icon hell. How many icons can you remember to use reliably all functions? 30? 50? 100? When touch interface uses restricted functionality, it does not matter. But if number of functions grows, it will.
6. The sixth problem: augmented reality looks exciting only because users have not played with it too much. It is restricted by necessity of visual contact with an object. Which makes it impossible to use for abstract conceptions. Performance? On one hand, augmented reality appeared to accelerate referring of real objects. Which works perfectly for immovable objects with constant geographic coordinates. But movable objects require at least image recognition, which works imperfectly.
As we may see, touch devices, in particular, and mobile devices, in general, are good in the niche, which they occupy today:
1. Mobility.
2. Casual communication (SMS style), telephony.
3. Casual entertainment.
4. Casual work.
5. Information, linked with geographic positioning and visual contact.
1980s: GRAPHICAL REVOLUTION
Of course, mobile devices may oust PCs, if the most of user will be happy with them. All advantages (games, entertainment, Internet) of personal computers, which attracted users in the past are available in mobile device now. What remains? The alternative of PC as a typewriter depends on reliability of voice recognition. That's all what an ordinary user wants. But there are a lot of tasks, which cannot be moved to mobile devices. And these tasks requires conventional interface of traditional operating systems.
The history of this interface passed through two key points: command line interface (CLI) and graphical user interface (GUI). Both stages are tightly coupled with hardware performance. Power of first computers was enough only for input-output of symbols. Gradually, performance reached the level, which allowed graphical interface. When you think on it, many do about affordable visualisation of data and applications, which made PCs so popular. Some may think about simplification, which let users to avoid CLI and manuals (to some degree). What matters more is GUI allowed increased complexity of applications, which extended usage of computers to many new domains.
However, graphical interface appeared at mass market around 30 years ago. At the current moment, he lost impetus and does not allow to increase application complexity even more. And how? Through further simplification? Nowadays simplified interface is somewhat "fashionable" thanks to minimalist style a la Apple and Google, thanks to mobile applications, which cannot be more complex because of physical restrictions. However, this simplification is achieved by decreasing functions with either throwing away or automating (which often only irritates, because an application makes wrong choices). That is, this is rather straightforward simplification, which decreases complexity of applications.
2000s: 3D REVOLUTION?
In some sense such minimalism (and accompanying simplification) is the reaction for unsuccessful attempts of graphical interface improving through 3D interface and virtual reality, which were quite promising 10 years ago. However, finally they become useful for restricted set of applications. Why? But what we can improve with them? 3D interface gives nothing special except of visual representation which is quite similar to real world one. This is where it converges with minimalism: they both intended to rather impress than serve efficiently.
The problem for 3D interface is humans prefer to see things as 3D but to manipulate with them in 2D. Realize, some information is written at a square or a cube. In the first case, we may see it fully (maybe with zooming or scrolling). In the second case, we may not see it completely but moreover we need additional ways for rotating cube, etc. That is, additional dimension makes information processing more complex. Of course, there are a lot of examples where 3D models are preferable (like vehicle design, etc). But in the most cases we would prefer 2D models. And even if a model has more dimensions (like Web which consists of 1D texts, represented at 2D pages, which linked with hyperlinks through the third dimension), we would prefer to make it two dimensional (pages are 2D anyway but "tunnelled" through the third dimension).
Virtual reality goes further and allows 3D interactions, that is, in the essence we deal already with 4D interface, which imitates real world. But is virtual reality efficient? We can ask it in even broader context: is "interface" of real world more efficient comparing with graphical computer interface? Look at things of real world. While they provide simple functions, their interface is ergonomic and well fit human hands. But as soon as functions become more complex and their quantity grows, we see buttons, switches, etc, that is, interface becomes very similar to 2D computer one. This is the key problem of any interface. While it covers a few functions, we can play with ergonomics and visual representation. As soon as complexity grows, learnability becomes more important.
2012: INFORMATION REVOLUTION?
Let's return to the original problem. Why does graphical interface allows to increase application complexity? Simplicity of GUI is at the surface. But looking deeper, GUI extended possibility of command line, because it packed commands into menus, their parameters into dialogs, and values into controls. Thus, (a) access to functions was simplified, because they can be found in one place, (b) access became reliable, because there are no more mistypes in names of functions and parameters, (c) validation can be done only for one element or can be avoided at all (because all values are packed in a list), etc. In the result, modern application can have about 200 functions only at top level, but with all dialogs, tabs, and other controls, their number easily grows to thousands. You may only guess how such number of functions may be managed by command line. In the essence, GUI have done quantitative leap in information ordering, which made applications more complex. But can this trend continue?
To understand that let us look how interface works in real life:
1. Any tool has own ergonomics, which is optimized for its usage.
2. As soon as quantity of tool functions grows, it starts using buttons and switches, and sometimes neglects ergonomics.
3. As soon as quantity of tools grows, we need reliable search of them. This can be resolved with groping by functional areas, or by shelves and boxes. But this works efficiently only if you understand and remember the principle of grouping. To explain this principle to others, you need to show it (which does not require calculations in mind). However, not everything can be shown visually (especially abstract conceptions), moreover, visualisation requires more time and size (if it's video) comparing with explanation. What's worse, fixing of physical grouping is not flexible, for example, if someone would violate it.
4. To be more flexible, we use natural language. But understanding of it is more difficult, because you need to link words to things, their location, relations between things and locations, etc, which require spatial and other calculations in mind.
The most important things in information ordering can be explained with Goedel incompleteness theorems (which states that any system may be either complete or consistent). Thus, a few functions may allow very minimal design, which can be easily understood by humans (that is, consistent for them). As soon a number of function grows (and a system become more complete), interface becomes more complex (and less consistent). The same theorems explain why explanation may be either brief but requiring calculations, or long but without them (that is, "speed vs. size"). This is true for both real world things and graphical interface, which cannot surpass the certain level of information ordering.
2012: SEMANTIC REVOLUTION
Similar balance between flexibility and efficiency we see in modern interface. CLI provides flexible approach, when you can easily combine functions and their parameters. GUI uses fixed order of elements, which is not flexible but more efficient. Both approaches are not flexible because their functions has fixed names (that is, if function is "copy file", you cannot call it as "write file").
But let's look at the situation from another angle. If we cannot have a system both complete and consistent, can we try to have both complete and consistent systems? This just means we may have several abstraction levels (from the most complete to the most consistent), which may be manipulated depending on circumstances. In own turn, this means, where we use information we need meaning. Information deals with fixed names as "hammer" (which may be used a sequence of 6 letters), which function could be only "driving a nail". Meaning deals with multiple aspects of a hammer as "a tool for impacting objects", etc, which properties may be applied to different situations. Its functions may include driving and removing nails, fitting parts, and breaking up objects, up to throwing and propping up.
To make meaning work we need the following innovations:
1. Human-friendly identification of meaning. Information, which usually represented as plain text, should be precisely identified (and refer to real world things or abstract conceptions). This would exclude ambiguities of natural language.
2. Human-friendly defining of relations. Meaning without appropriately defined relations may be incorrect. For example, "a hammer is at the second shelf in the left box" may mean that the given shelf is inside the box or this box is at the given shelf.
3. Semantics usage inside hypertext, which makes it (with identification and relations) human-friendly. And this is, in fact, simplified Semantic Web.
4. Semantic wrapping. All information elements (files, graphical controls, web page elements, etc) do not have meaning by themselves. Usually it is attributed by human mind. However, to order information efficiently, we need meaning directly linked with these elements.
5. Notion of textlet, which may (a) be requested with questions in a human-friendly form, which is quite close to natural language, and (b) responds with answers with the same form.
6. Context is needed to make meaning area more narrow or wider. For example, a context of tools may narrow to one of hammers, but also we may extend a context of hammers to one of tools.
7. Semantic line interface (SLI) may combine features of command line (CLI) and graphical interface (GUI). CLI features may include top level access to any identifier and an order of identifiers which is similar to natural language one. GUI features may include convenient information representation in checkboxes, lists, etc.
Such approach is more appropriate for several conceptions, which may work more efficiently under new circumstances. Thus, voice control may be more efficient coupled with SLI, which is more similar to natural language. Augmented reality and image recognition may use direct references to real things, which would be accessed by users easier. But what matters even more is this approach is a part of broader semantic ecosystem, which embraces not only interface and its elements, but also other parts of OS, Web, etc. This, in own turn, means that an ordinary user may access even to programming interfaces (semantically wrapped and represented as textlets).
More details you may find in Future of operating system and Web: Q&A
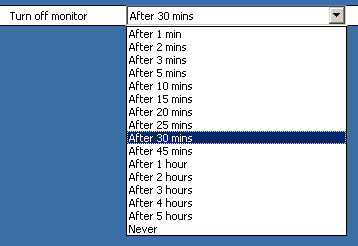
The example of SLI you may find below: how to set up timeout for monitor turning off? Almost any function is hidden in hierarchy of menu/dialog/tab calls, which makes their calls are not very intuitive.

Instead of that we may use SLI, which would provide top-level access for any function and combines certain features of both CLI and GUI. Thus, you can start typing "turn off" and SLI would hint which identifiers are available (possibly, restricted by some context). After "turn off monitor" function found, SLI would display the corresponding control.
Hi,
ОтветитьУдалитьthis is interesting. I have thought about this topic very much.
Check out ActiveType.
ОтветитьУдалитьhttp://www.scriptspot.com/3ds-max/scripts/activetype?page=1
It's inspired by applications such as The Foundry's Nuke and Sideshow's Houdini. In both applications you press a button and then type in the command (with autocomplete lists). So if you want to blur you simply press "TAB, bl, ENTER" and a blur node is created.
ActiveType for 3ds Max of course combines the two as well, however I do like the idea of implementing dynamic GUI controls in your example.
The challenge though is the same as trying to 'pilot' someone else using a computer.
maybe you'll find TermKit interesting: http://acko.net/blog/on-termkit
ОтветитьУдалитьThere are three User Interfaces....Naturally!
ОтветитьУдалитьhttp://abstractionphysics.net/pmwiki/index.php#Primary_computer_user_interfaces:
i've thought on this for a long time as well, at least since 1991, roughly when i first used X Windows.
ОтветитьУдалитьone way to achieve this is to make a list of keywords for each action, keywords being derived from the PATH to the action plus the keywords in the dialog box or web page where tthe action occurs.
in the Power Options example the author has provided, we can get the following keywords relatively easily:
Control Panel\Hardware and Sound\Power Options\Edit Plan Settings\
Turn off the display
Choose when to turn off the display
Power Saver
now, if the command given (either typed or via voice) is "set monitor time out," the SLI (semantic line interface) should do this:
make a tag cloud that includes, say, "monitor", "display", "VGA", etc. "Time out" can indicate "end", "off" etc. and so on. this is still quite brittle, but no so much as how strict things are today, viz. pathnames must be EXACT in order to perform a function.
"go to control panel, set monitor time out to 5 mins." is easy enough to interpret with today's technology. you see this EVERYDAY when google gives you suggestions as you type in your search.
it will probably come to an OS near you very soon. unless Chrome itself is the OS.
Thanks for all comments.
ОтветитьУдалить1. Of course, similar ideas can come into mind of other people too. However, why, then, there is still nothing even close to SLI?
2. Yes, there are three interfaces: CLI, GUI, and different sorts of programming interfaces. All this covered by my articles (you can check the link above). Namely this article just omit APIs because of a lack of space. ;-)
3. All of you miss one simple though important point: this text is not only about interface. Semantic interface is only one of consequences of semantic ecosystem, which could covers all parts of OS, Web, etc.
"To make meaning work we need the following innovations:
ОтветитьУдалить1. Human-friendly identification of meaning. Information, which usually represented as plain text, should be precisely identified (and refer to real world things or abstract conceptions). This would exclude ambiguities of natural language.
2. Human-friendly defining of relations. Meaning without appropriately defined relations may be incorrect. For example, "a hammer is at the second shelf in the left box" may mean that the given shelf is inside the box or this box is at the given shelf."
This is a pretty tall order. The trouble here is humans are pretty bad at this. We constantly miscommunicate with each other because we have different assumptions about relationships or meanings attached to a term. Even the smartest of AI is going to do no better than a person at interpreting the "Sense" or the "Reference" of a given term, let alone lengthy ambiguous string of related terms. (For more on how incredibly hard a problem this is see "On sense and reference" by Gottlob Frege) Best case scenario we can implement semantic tagging systems which make best guesses possible based on the aggregate of potential meanings and relationships attached to a given term. This is an inherent limitation built into any system (humans included) which process semantic strings of input. There is no way to "exclude ambiguities of natural language" and attempts which depend on it are doomed to fail.
You are thinking in right direction. When you'll start to write some software?
ОтветитьУдалитьSpring Roo project provides a very interesting CLI which uses context effectively to present commands to a user.
ОтветитьУдалитьI think we are gradually moving towards a semantic ecosystem.
Yes, machines better treat semantics, when we are talking about big volume of data. However, there is a trick. Natural language text already has meaning and "references". The task for humans is just to make it more precise. Tagging is not good because it classifies information, which is arbitrary and may have many variants. Whereas identification of information is unique. Yes, humans may miscommunicate information, but this could be done with plain text too.
ОтветитьУдалитьMoreover, of course, human-friendly identification will occur in computers, so it will be certainly helped by machine. Moreover, identification and defining relations is not really tall order. Of course, it could be in the case of some vague or very abstract information by itself. But in this case, even text can be meaningless if you don't understand what it is talking about. But a creator of information should know meaning. Identification may sound as too elevated word, but in fact, it can be the process of choosing the right reference from several ones. Defining relations may sound elevated too, but, in fact, it is the process of just linking words to be clear what relates to what.
More lengthy answer in Can humans treat semantics? Can machines treat natural language?
ОтветитьУдалитьHas anyone tried the Mozilla Ubiquity project? Or the Gnome-Do project? Both of these present an auto-completing semantic command line for doing "anything" (limited by what plugins are active), Ubiquity from the browser and Gnome-Do from the desktop.
ОтветитьУдалитьMozilla Ubiquity, Gnome-Do, Alfred, and other similar tools are too restrictive and aimed correspondingly for Mozilla browsers, Linux, Mac, etc. Moreover, they are text-based, which means they cannot be fully semantic.
Удалить